データにまつわるトラブル事例(3)〜システム統合・システム連携編〜

過去2回、昔からよくある単一のシステム内で起きる問題を取り上げてきました。(情報システム編、産業システム編)今回は、最近増えている、システム連携・統合の問題の事例について取上げます。
DXの推進が世の中の趨勢となってから、企業の業務の合理化のために、これまで個別に運用していた企業内のシステムを統合したり、より価値の高いサービスを提供するために外部システムとデータ連携を行うなど、複数のシステムを繋ぎ合わせたる案件が増えています。これを実現するための手法や、繋ぎ合わせる手段であるデータ連携ツールなどについては、色々なところで言及されています。
しかし、個別に設計されたシステムを繋ぎ合わせることは容易ではなく、色々な問題が発生しています。その中でも大きなトラブルになるのは、繋ぎ合わせる手段の問題よりも、連携・統合するデータそのものに関連するものです。
1. データの不整合
現象
他システムから送られてきたデータが意図したものと違うため、システムにデータが格納できなかったり、間違った結果を表示してしまったりするケースです。個別に設計されたシステムを連携・統合する場合、どうしても各々のシステムでのデータの取り扱いに不整合が起きてしまい、発生しやすい問題です。システムテストなどで発見されず、運用が開始されてから顕在化することも多く、大きなトラブルになりやすい傾向があります。また、システム連携の場合、異なるベンダーが開発したものを連携する場合、問題が起きると、どちらでどう問題を解決するかベンダー間で揉めることが多く、厄介なトラブルになりがちです。
原因
システムを連携する際には、データをやり取りするインタフェース仕様を検討することになります。各システムで必要なデータ項目やデータフォーマットなどを確認し仕様を決定します。ここまでは良いのですが、落とし穴になるのはデータの「意味」と「制約」です。これらについての確認や合意が十分にできていないままに、各システムでの勝手な思い込みで設計を行なったことが原因で問題は起こります。
「データにまつわるシステムトラブル事例(1)〜情報システム編〜」のデータ移行の話でも出てきた、以下のような問題がよく起きます。
- 重複したレコードがある
- 値が入っていることが必須のカラムに値が入っていない
- データが想定していた値の範囲に入っていない
- テーブルのカラム名が曖昧なことによる意味の誤解
防止策
情報システムのデータ移行の問題と同じで、データに関する検討・調査とテストを事前に計画を立ててしっかり行うことが基本的な防止策になりますが、システム連携・統合案件の場合に難しいのは、それを「誰がやるのか」が曖昧になりがちなことです。
複数のシステムの開発チームが関わる話なので、開発チーム間で協議して決めてくださいと言うのは大抵うまくいきません。色々な問題が出てきますが、データを提供する側と使う側で問題の見え方は違います。データを使う側からはデータ品質の問題に見えるものも、データを提供する側から見ると使う側の検討不足に見えるのです。問題の解決を開発チーム間の協議に委ねても、いつまで立っても解決しません。
各々のチームとは独立した、連携するデータに関して責任を持つ、各システムの開発チームからは独立した、第三者的な役割を置くことが必要になります。
2. 多数のシステム間のデータ連携
現象
連携するシステムが増えてくると、システムの組合わせごとにデータ連携の実装が必要となったり、組合せの数だけ前述のデータ不整合の問題が繰り返し出てきてしまいます。結果として、データ連携ソフトを維持するための作業が大きくなり、高コストになってしまいます。
原因

2つのシステムを連携させる場合は1対1のデータ連携でも良いのですが、連携するシステムの数が増えるとこのやり方は非効率で高コストなやり方になってしまいます。1対1のデータ連携以外の方法を検討すべきです。
防止策
上記の問題を解決する方式としては、以下が考えられます。
データベースの共有 システム間で共用するデータを管理するデータベースを外部に構築し、これを介してデータ連携を行う方式です。
EAIツールの利用 各システムとの接続、データのフォーマットの変換、データのルーティングなどの機能を持ち、データのやり取りを一元的に行うEAI(Enterprise Application Integration)ツールを導入する方式です。
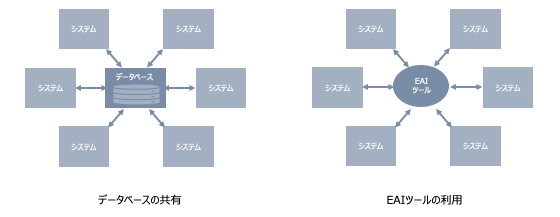
ただし、どちらの方法も、各システムとは独立した共用データベースシステムやEAIシステムの開発・運用チームが必要になり、このためのコストがかかります。コストに見合うかの判断が必要です。
3. データ量の問題
現象
システムの処理能力を超えた想定よりも大きいデータ量が高い頻度で送られてくると、システム全体がスタックしてしまうことがあります。また、EAIなどのデータ連携ソフトウェアなどを使っている場合、これ自体がボトルネックとなってしまって、全体の処理に影響を及ぼす場合もあります。
原因
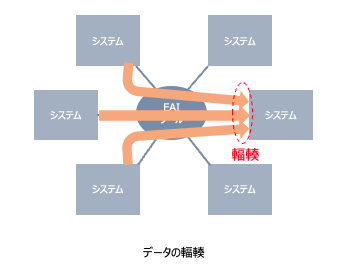
複数システム間のデータフローが、単一のシステムに集中してしまうような場合に問題は起きやすくなります。複数のシステムから、イベントデータを受け取るシステムがあった場合、複数システムから同時にバースト的なデータを受け取ってしまうと、一時的にデータの処理のために高負荷になってしまう、「データ輻輳」と呼ばれる状態になります。また、設計時にシステム間で十分な取り決めをしていなかったために、本来不要なデータを不要なタイミングで送ってしまったりすることも、トラブルの原因になります。
防止策
最初にデータ量と頻度を見積り、それに合わせたシステム設計をすることが基本になります。データの内容に関する確認だけでなく、データ量とその頻度についても確認が必要です。連携仕様を策定する際には、冗長なデータの送信は避け、必要なものを必要な頻度でやり取りすることを心がけるべきです。
EAIなどのデータを一箇所で管理するデータHUB型のアーキテクチャの場合、データHUB自体がボトルネックにならないように設計する必要があります。特定のシステム間の連携で突出してデータ量が多い場合には、そこだけ別経路で連携するなどの設計が有効になる場合もあります。
さらに言うと、システム間であまりにも多くのデータをやり取りをしないといけなくなっっているのは、元々の各システムの役割分担がおかしいのかもしれません。役割を見直すとやり取りするデータ量が格段に減少することもあります。
4. システム統合におけるマスターデータの問題
現象
マスターデータとは、企業などの業務活動に関連する共通概念や項目を表現したものであり、製品データ、購入品目データ、顧客データ、組織情報データなどのことです。システムの連携・統合の際に、必ずと言って良いほど問題になるのが、これまでシステムごとに管理されてきたマスターデータをどうするのかという問題です。
システムの統合を行う場合、関係するマスターデータは、何らかの形で共通化しなければならないのですが、これらのマスターデータがうまく整備できず、システム統合計画が頓挫するケースも多くみられます。
すでに、個々のシステムで定義され運用されてきたマスターデータがあり、これらをずっと使ってきた人や組織がいることが問題を難しくします。これら全ての人や組織の要求を満足させるようなマスターデータやそのデータモデルを設計するのは、かなり難しい話なのです。
原因
マスターデータの整備で具体的に問題になることが多いのは、以下のケースです。
コードの標準化
例えば、購入品目データなどで、同一品目であっても個々のシステムで異なるコードを与えてしまっているということはよくあります。このコードを標準化する際に問題が起きます。異なるものの対応関係がわかっていて、お互いを紐付けできるのであれば良いのですが、実際にはコード体系自体が異なっており、単純には紐付けできない場合があります。例えば、以下のような場合です。
- コードに「副番」が含まれている場合。どういう場合に副版がつけられるかなどは組織によって異なっていたりします。
- コードの桁数に意味を持たせている場合。例えば10桁のコードのうち、下2桁は「製品のバージョン」を表すなど。
また、これまで、このコード体系を元に仕事をしてきたことに慣れてしまった人や組織は、コードを新たに変えることに前向きではない場合も多く見られます。
組織情報の標準化
組織と所属に関するデータは、各種業務システムのマスターデータとして、企業内のシステムのほぼ全てのシステムに必要になるものです。しかし、あらゆる用途に柔軟に使えるようにするためには、以下を考慮したかなり複雑なデータモデルを設計する必要があります。
- 組織は階層構造になっており、かつ組織改変などでその階層構造の親子関係や階層の深さなどが変わることがある。
- 組織に所属する人員の中には、「主務(本務)」と「兼務」がある。
- 組織改変時に、トランザクションデータを過去の組織から現在の組織に紐付ける必要がある。例えば組織の統廃合により、廃止になった組織のデータを新たな組織のデータに紐付け直すなど。このためには、組織の過去の履歴を保持しておく必要がある。
データベースが複雑になりすぎると、これを使うアプリケーション側の処理も複雑になってしまい、ソフトウェアの変更に大きなコストがかかってしまいます。
防止策
マスターデータの統合が難しいのは、マネージメントやガバナンスの側面と、データに関する技術的な側面の両方を解決する必要があるためです。そのためには、組織的な取り組みが必要になります。
企業の各部門と調整しながら標準化を進め、標準化したものを継続して維持していくことが必要になります。マスターデータのためのデータモデルを設計し管理システムを構築し、さらに使う側のアプリケーションソフトウェア開発チームのサポートを継続的に行うことも必要です。マスターデータ管理(Master Data Management : MDM)と呼ばれる、このような活動を組織的に行うことが求められます。
余談 〜根源的な問題〜
上記の事例に共通して言えることは、個々のシステムとは別に、複数のシステムに関連するデータをマネージメントする役割が必要であると言うことです。関連するデータを標準化し、各システムにデータ連携手段を提供し、これを継続的に運用していく役割です。
しかし、現状ではこのような組織を置くのは、なかなか難しそうです。多くの場合、企業や組織の各種システムの開発や運用は、長年複数の情報システムベンダーで分け合っており、その中にあるデータも囲い込んでしまっています。別の組織にデータを委ねるとなると、相当な抵抗が予想されます。
データを使っている張本人である会社や組織の情報システム部門が、データマネージメント組織を主導できれば良いのですが、各システムはベンダー任せになっているため、残念ながら複数のシステム全体を把握しトータルでのデータ設計ができるような実力を持てていません。これは、日本の多くの企業で見られる、業界の構造的な問題なのでもあります。
ただ、今後、徐々に状況は変わっていくのではないかと思います。これまで情報システムの「ユーザ企業」の立場であった企業も、情報システムがこれだけ重要になってくると、最早単なるユーザではいられなくなりますので、情報システムのための人員は増え強化されていくでしょう。これまで情報システムベンダーにいたIT人員はユーザ企業側に移転していく流れになると思います。逆の見方をすると、あまり変わラズ「ユーザ企業」に留まってしまう企業や組織は、徐々に競争力を失っていくのだろうと思います。
(了)